
Dois anos atrás a conversa era outra
Quem trabalha em operação de contact center conhece bem o paradoxo da monitoria: a área que mais influencia a qualidade do atendimento é, também, a que enxerga menos. A regra silenciosa do mercado sempre foi a mesma — auditar de 2% a 5% das chamadas, sortear amostras, treinar o avaliador para julgar com critério. Os outros 95% a 98% das ligações ficavam fora do radar, e era nesse espaço cego que moravam as não-conformidades que ninguém pegava.
Em 2024 essa equação começou a virar. Em 2026 ela já virou. Plataformas como NICE, Verint, Five9, Genesys, Observe.AI, Cresta, Talkdesk e MaestroQA hoje vendem como tabela básica algo que era impensável há três anos: monitorar 100% das interações automaticamente, com nota, com justificativa e com trecho citado. O mercado brasileiro de speech analytics deve sair de US$ 95,7 milhões em 2025 para US$ 352 milhões em 2035 (Market Research Future), e a velocidade de adoção é mais um sintoma do que causa: quando a tecnologia fica boa o suficiente, o argumento de "amostragem é o que dá" some.
Este post é um mapa do que está acontecendo, traduzido para quem precisa decidir o que comprar, o que cobrar do fornecedor atual e como conversar com a diretoria sobre o assunto.
As três gerações que hoje coexistem dentro da mesma plataforma
Quando um fornecedor diz "nós temos IA", ele está, na prática, oferecendo uma mistura de três tecnologias diferentes que conviveram historicamente em camadas distintas. Cada uma resolve um problema, cada uma tem um custo, cada uma tem um limite. Entender as três é a forma de não pagar caro por uma feature que você já tem nem ficar de fora de uma que mudaria o jogo.
Geração 1 — A camada que ouve o ritmo, não as palavras
A análise mais antiga não transcreve. Ela mede o sinal de áudio diretamente: quanto tempo o agente falou, quanto tempo o cliente falou, quantos segundos de silêncio teve, quantas vezes os dois falaram por cima, quão rápido foi o ritmo da conversa, se houve alteração de tom. São métricas que rodam em centavos por mil chamadas e cabem em 100% do volume desde sempre.
Para o gerente de operação, isso traduz coisas concretas: silêncio prolongado costuma ser pesquisa em sistema mal indexado; agente falando muito mais que o cliente em chamada de retenção é sinal de script lido sem escuta; "overtalk" é geralmente cliente irritado tentando interromper; ritmo acelerado pode ser ansiedade ou agente que quer encerrar logo. Cogito, comprada pela Verint em 2024, construiu o negócio inteiro em cima de mais de 200 sinais como esses processados em tempo real (Cogito). NICE Real-Time Authentication usa o mesmo tipo de sinal para autenticar cliente em 3 a 5 segundos só pela voz.
O que mudou: nada. Essa geração continua igual. O que mudou é que ela parou de ser o ponto alto da arquitetura — virou a triagem barata que aciona as camadas caras só quando faz sentido.
Geração 2 — Regras escritas, scorecard automático
A geração que dominou os contratos entre 2010 e 2022 transcrevia tudo e depois deixava o analista escrever regras: categoria "objeção de preço" são as frases X, Y, Z ditas pelo cliente dentro de 8 palavras das frases A, B, C. Categoria "agente identificou-se" são as frases do agente nos primeiros 30 segundos. Categoria "menção à concorrência" é a lista de nomes do setor.
CallMiner com a EQL (Eureka Query Language), Verint com Categories e Themes, NICE Nexidia com indexação fonética, Genesys Cloud com Topics e Programs — todos convergiram para o mesmo modelo de regras booleanas com proximidade e filtro de canal (CallMiner, Genesys).
Em linguagem de operação: o sistema entrega um scorecard preenchido automaticamente onde "sim/não" é decidido por regra. "Cliente reclamou de cobrança?" — verdade se a categoria correspondente disparou. Cada item tem peso, soma o total, sai a nota. Roda em 100% das chamadas em CPU, dá para auditar a regra inteira em texto, e quando o agente contesta, o supervisor mostra exatamente qual frase, em que segundo, disparou o sinalizador.
Essa camada não morreu. Pelo contrário: continua sendo o substrato regulatório aceito por Anatel, Susep, Procon e perícia trabalhista. Regra escrita é determinística, explicável e versionável. LLM responde, regra audita.
Geração 3 — Perguntar em português e receber resposta em segundos
A virada dos últimos dois anos. Em vez de configurar regex, o supervisor escreve em texto livre: "o agente ofereceu o produto complementar?", "o cliente mencionou a concorrência?", "por que essa venda não fechou?". O LLM lê a transcrição segmentada, responde sim ou não, atribui pontuação e — o detalhe que muda tudo — cita o trecho exato da fala que sustenta a resposta, com o timestamp clicável para o supervisor ouvir.
Observe.AI vende exatamente isso como Auto-QA: o sistema preenche o formulário humano e mostra a evidência (Observe.AI). MaestroQA tem o AskAI, onde o usuário pergunta em linguagem natural sobre listas de até mil conversas ("o que os clientes do estado X estão reclamando esta semana?") (MaestroQA). Cresta tem o AI Analyst. NICE tem o Enlighten Actions, voltado para a diretoria fazer perguntas tipo "por que o CSAT caiu na região Sul?". Talkdesk tem o QM Assist Evaluator. Dialpad tem AI Scorecards com citação clicável. Sprinklr tem o Contextual Model que olha o caso inteiro em vez de mensagem a mensagem.
Cinco coisas viraram tabela nessa camada:
A primeira é a citação literal obrigatória. Toda resposta do LLM precisa estar ancorada num trecho específico da gravação. Sem isso, contestação do agente vira disputa de palavra, e a plataforma perde credibilidade no primeiro confronto. Pesquisa acadêmica recente (FECT, arXiv 2508.00889) já está medindo factualidade de claims de LLM sobre transcrição de call center — sinal de que o setor reconheceu o problema do "alucinar com confiança".
A segunda é a calibração progressiva como parte da experiência, não como bug. Humano e máquina avaliam lado a lado, supervisor concorda ou discorda, e o sistema aprende. Observe.AI vende isso explicitamente como ciclo de tuning, MaestroQA tem template library com grade lado a lado.
A terceira é o coaching automático escrito. O sistema redige o feedback que o supervisor entregaria, com pontos fortes e pontos a melhorar, e o operador pode receber antes mesmo da reunião de feedback formal. Reduz dependência da agenda do supervisor.
A quarta é interface conversacional sobre o acervo. A diretoria deixa de ouvir gravação ou de ler dashboard e passa a perguntar. Gong popularizou em vendas com o "Ask Anything"; o contact center copiou a UX.
A quinta é multi-LLM por design. Verint Open Platform e MaestroQA deixam o cliente escolher o modelo (Claude, GPT, modelo aberto, modelo nacional) por jurisdição, custo ou idioma. Ficar preso num único provider virou fraqueza competitiva.
O pipeline em camadas que sustenta tudo isso
A pergunta natural do gestor de operação é: se cada chamada precisa de transcrição mais regras mais LLM, o custo não explode? Não, porque ninguém roda tudo em todas as chamadas. O padrão de arquitetura que se consolidou no mercado tem nome em patente americana ("multi-pass speech analytics", USPTO 9171547) e já foi formalizado em paper recente da Cisco (arXiv 2503.19090).
A ideia é simples e tem cara de operação de BPO bem feita: as camadas baratas rodam em todo mundo, e só disparam as camadas caras quando vale a pena. Acústica e metadados (silêncio, overtalk, duração, transferências) rodam em 100% por centavos. Transcrição mais regras rodam em 100% por alguns dólares por mil chamadas. NLP leve (sentimento, classificação) roda em 100% também. O LLM caro, que dá a resposta sofisticada com citação, roda em 5% a 20% das chamadas — só as que as camadas anteriores sinalizaram como dignas de atenção (compliance flag, score baixo, sentimento ruim, supervisor pediu, agente novo).
É o oposto do que muita operação faz hoje (sortear 3% no aleatório) e o oposto do que um fornecedor desavisado faria (jogar LLM em tudo). É monitoria do problema, não da sorte.
O que muda no dia a dia da operação
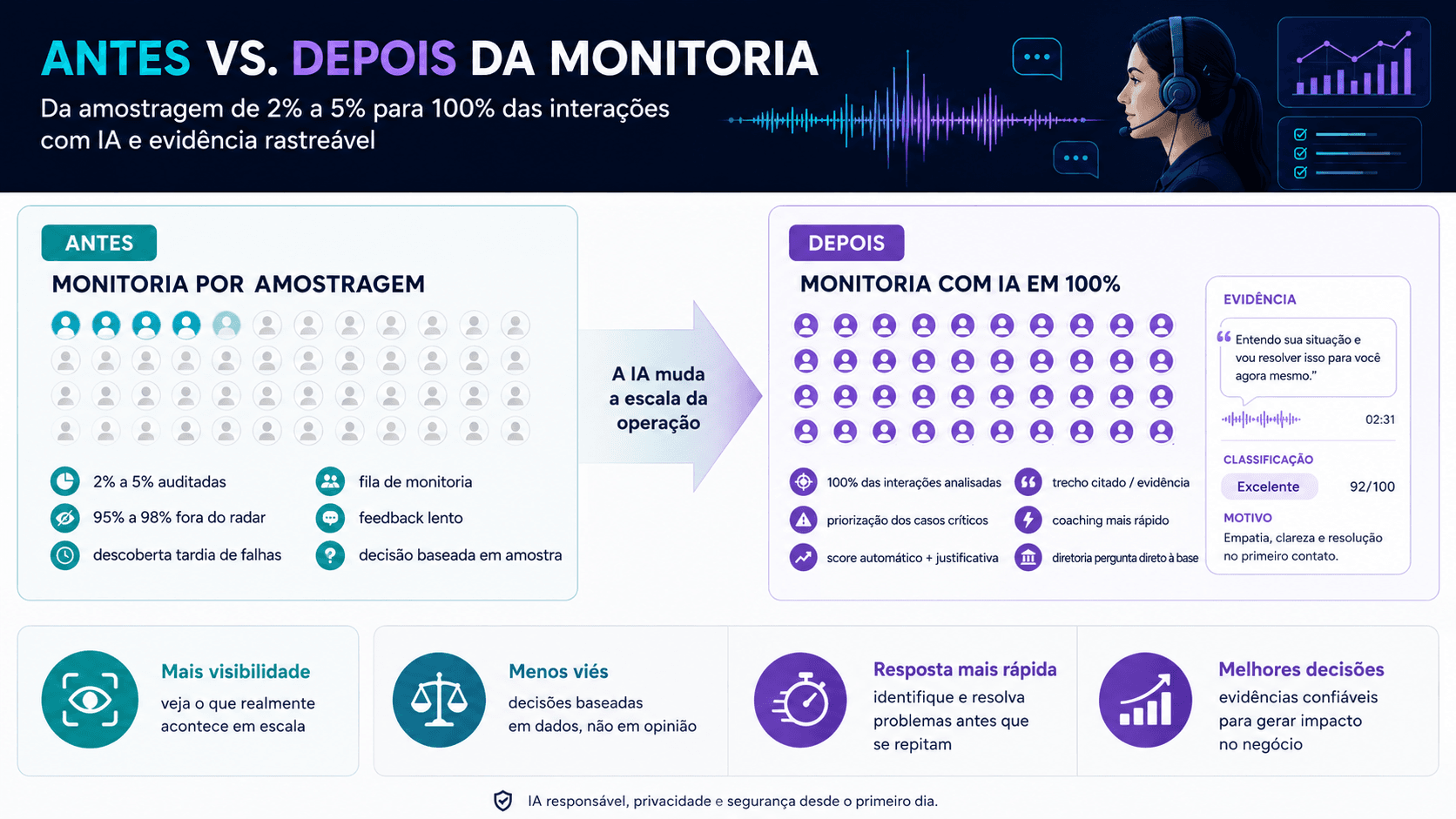
Quatro mudanças concretas que um gerente de BPO percebe nos primeiros 90 dias depois de implantar a coisa direito.
Cobertura passa de 3% para 100%. Compliance que escaparia da amostra é capturado em tempo quase real. Não é só "monitorar mais" — é monitorar diferente. Em vez de sortear chamada para julgar tudo, o sistema julga tudo e prioriza o que merece olho humano.
A monitoria deixa de ser bottleneck. O scorecard humano vira scorecard preenchido automaticamente, e o monitor passa a calibrar e contestar, não preencher. Operações que tinham fila de monitoria atrasada de dias passam a operar em D+0 com folga.
Coaching para por escrito sem esperar a agenda do supervisor. Cada operador recebe feedback redigido, com trechos da própria chamada citados, em minutos depois da ligação. Quando o supervisor faz a reunião de feedback, está só ratificando o que o operador já viu — economiza tempo, reduz atrito.
Diretoria perguntando direto à base. O diretor de operações deixa de pedir relatório e passa a perguntar: "o que mudou nas reclamações esta semana?", "as objeções de preço aumentaram desde a campanha nova?", "o time da Joana está mencionando concorrente mais que os outros?". Resposta em segundos, com lista de chamadas para drill-down.
O que não mudou — e o que isso significa
Vale a parte que costuma escapar nas demos vendedoras: regulação não mudou, contestação trabalhista não mudou, fluxo de feedback assinado não mudou. Anatel continua exigindo gravação integral por seis meses (Resolução 632/2014) e consentimento explícito em ofertas (Resolução 777/2025). Perícia trabalhista vai continuar pedindo regra escrita, segundo exato e gravação preservada quando o operador contestar uma demissão. LGPD continua tratando voz como dado biométrico sensível.
A consequência prática é que a Geração 2 (regras + scorecard auditável) não morre — ela vira o substrato regulatório por baixo da Geração 3. O LLM responde, mas a regra é o que se mostra para o perito. Por isso quem está construindo plataforma nova hoje, em vez de aposentar as regras, está empilhando: regra valida o que é auditável; LLM cobre o que não cabe em regra.
Três armadilhas comuns na adoção
A primeira é comprar pela demo. Demonstrações de speech analytics são feitas em chamadas curadas, com áudio limpo, sotaque neutro e cliente educado. A operação real tem ruído de PSTN, sotaques regionais, dois ou três interlocutores falando juntos, agente lendo script colado. Whisper, hoje o estado da arte em transcrição aberta, fica em 8% a 15% de WER (taxa de erro por palavra) em PT-BR limpo e sobe para 17% a 22% em telefonia ruim (VexaScribe). Toda regra e todo prompt que dependem da transcrição herdam esse erro. Pedir piloto em 200 chamadas reais da sua operação, com áudio do seu gravador e idioma da sua base, é a forma mínima de não ser enganado.
A segunda é não exigir citação literal. Se a plataforma só te dá um "sim/não" sem mostrar onde, na chamada, a coisa foi dita, ela está só te empurrando uma opinião computacional. Na primeira contestação séria, vira a sua palavra contra a do agente. Citação clicável no áudio é o teste de fogo.
A terceira é assumir que LLM substitui regra. O mercado já fez essa curva: começou em 2023 dizendo que LLM resolveria tudo e voltou em 2025 dizendo que LLM mais regra é o padrão. Quem mantém as duas camadas em paralelo (regra auditável + LLM gerador de evidência) é quem está conseguindo passar em compliance regulado. Plataforma que joga regra fora tem dificuldade na primeira inspeção da Anatel ou na primeira perícia.
Para onde vai daqui
Três movimentos visíveis nos próximos dezoito meses para quem está atento ao mercado.
O primeiro é convergência de canais. Voz, chat, e-mail, WhatsApp e ticket vão para a mesma camada de análise, com o mesmo scorecard, o mesmo Auto-QA e a mesma busca conversacional sobre o acervo todo. NICE Nexidia e CallMiner já trabalham isso há tempo, mas é em 2026 que o discurso bate o produto.
O segundo é agent assist em tempo real virando expectativa, não diferencial. Cresta, Cogito, Dialpad, Talkdesk Copilot, NICE Enlighten Copilot — todos correndo para colocar prompts e sugestões na tela do agente durante a ligação. Vai chegar a hora em que operação sem assist será como operação sem URA: vai parecer dos anos 2000.
O terceiro é bolsa de modelos, não modelo único. O cliente escolhe qual LLM roda para cada tipo de análise, balanceando custo, idioma e residência de dados. Operações sensíveis a LGPD vão preferir modelos hospedados no Brasil (BRAZILIANS-LLM, Maritalk) ou em provedores com cláusulas claras. Verint Open Platform e MaestroQA já saíram na frente nessa arquitetura.
Fechando
A linha que separa um BPO competitivo de um BPO que só sobrevive em 2026 não é mais "tem ou não tem speech analytics". É outra: monitora 100% das chamadas com evidência rastreável, ou ainda sorteia 3%? Tem citação clicável da gravação ou só dashboard colorido? Deixa diretor perguntar à base em português ou só entrega relatório?
A tecnologia para responder "sim" a essas três perguntas existe, é provada, está disponível tanto em fornecedor global quanto em opções nacionais com adesão à LGPD nativa. O que decide quem vai usar bem e quem vai jogar dinheiro fora é a clareza sobre as três camadas — qual problema cada uma resolve, qual roda em todo mundo e qual roda só nos casos selecionados, e onde está o tribunal final quando o agente contestar.
A IA passou a ouvir todas as chamadas. A pergunta agora é o que a operação vai fazer com isso.
Para se aprofundar
- Verint Speech Analytics — plataforma de referência da Geração 2 que evoluiu para multi-LLM com a Open Platform.
- NICE Enlighten Actions — interface conversacional para a diretoria perguntar à base.
- Observe.AI Auto QA — referência prática de citação literal e calibração humano/máquina.
- Cresta AI Analyst — exemplo de "Ask Anything" no contexto de contact center.
- MaestroQA AskAI — exemplo público de pergunta livre sobre acervo de até mil conversas com escolha de modelo.
- LLM-Based Insight Extraction for Contact Center Analytics — Cisco/arXiv — paper de 2025 que formaliza o padrão de pipeline em camadas com roteamento por custo.
- FECT — Factuality Eval of CC transcripts (arXiv) — benchmark acadêmico para medir factualidade de respostas de LLM sobre call center.
- Patente USPTO 9171547 — Multi-pass speech analytics — descrição patentária do princípio "camada barata aciona camada cara".
- Mercado brasileiro de Contact Center Analytics — Market Research Future — projeção de 2025-2035 para o Brasil.
- Whisper accuracy / WER por idioma — referência prática de qualidade de transcrição em PT-BR.
Texto produzido em maio de 2026 a partir de pesquisa sobre fornecedores globais (Verint, NICE, CallMiner, Genesys, Five9, Observe.AI, Cresta, Level AI, MaestroQA, Talkdesk, Sprinklr, Dialpad, Cogito, Gong) e o mercado brasileiro de contact center analytics.